Enabling configurable projects for ML experiments through GIN
Motivation
We encountered situation when we find ourselves in a very high experimental setup. The task given to us has many approaches out there in form of papers. On the top of that we have our own experience and gut feeling on what can help to achieve better results. Now we have many tools out there to track experiments and log hyper-parameters. But is that enough? There are two questions come to my mind:
- Can we log everything ? e.g. what kind of augmentation do we use for a particular run - Gaussian blur? if yes, what’s the kernel size ?
- Even if we do, how do we ensure maximal flexibility and visibility of that? How do we make most of the stuff configurable in the code without turning the code-base in to a total mess ?
One desirable property of combining both a good configurable project and experiment tracking tool
- is to keep all configurables in a configuration file,
- use experiment tracking tool to track metrics and losses and maybe some hyper-parameters. But these things are not only configurables right? What if I want to change the architecture of the generator network? Or what if I have changed the dataset by adding 100k images to it?
- upload configuration file as an artifact
These approach seems to enable first concern from above - now we can literally keep all configurable aspects of the project in the configuration file. And log everything we want to track over time.
Now how do we enable configuration flexible without harming the code-base ?
Let’s go over an example…
Pytorch Lightning example - vanilla
Here I would like to talk about gin-config that does not get attention it deserves. Maybe it is too complicated or maybe google folks were not able to motivate it enough in their “documentation”. So I have decided to spend some time to create a walkthrough of a “real world example” and show where it shines. Real world is a bit stretch here, cause it’s gonna be….good old MNIST example.
basic-gan example can serve us a guinea pig to understand the benefits of having gin-config around. Instead of having one single file containing all the code from example I have tried to create a project like structure:
run.py - entry point of the application
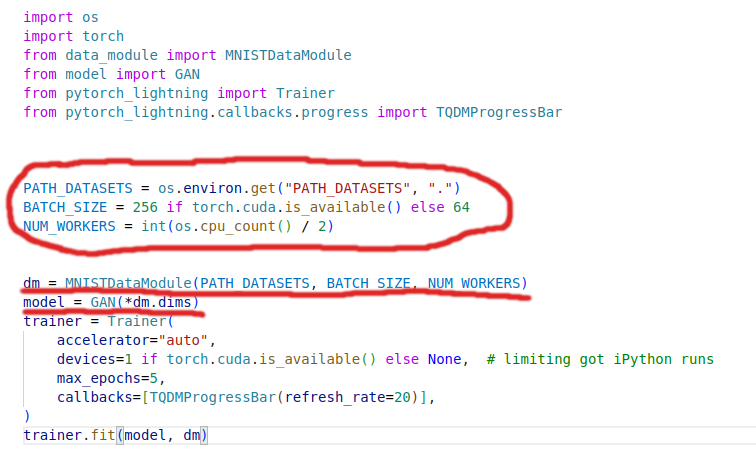
data_module.py - PytorchLightning DataModule - responsible for DataSet and DataLoader creation
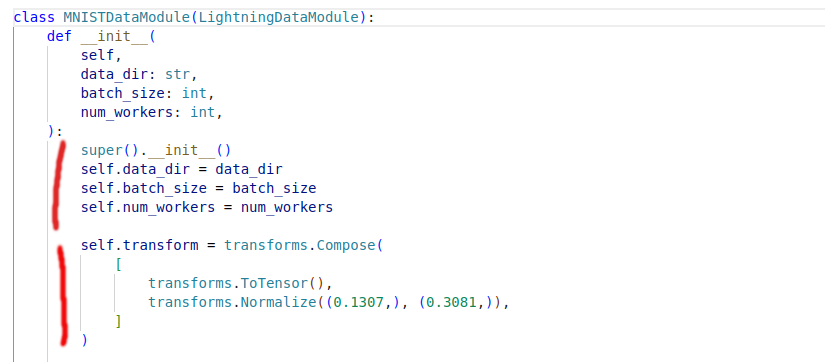
model.py - contains the PytorchLightning module and training logic
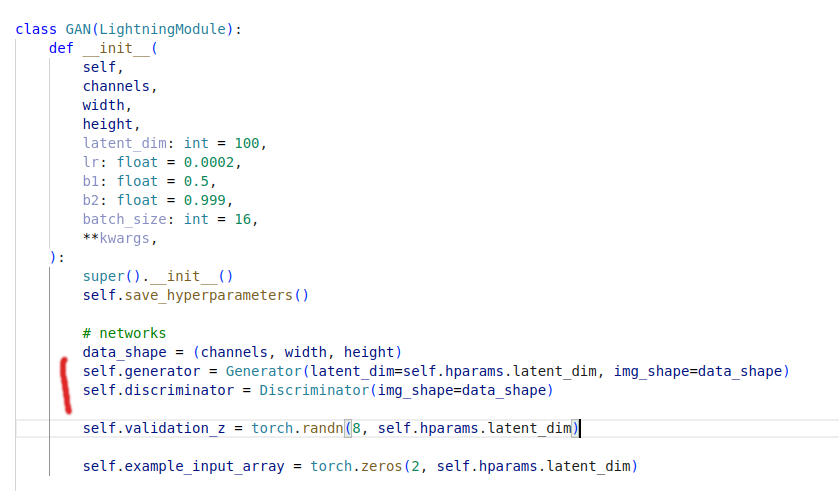
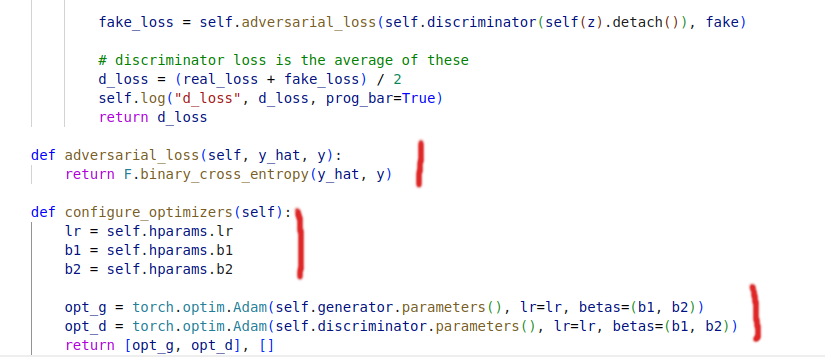
Red parts above mean that ideally I would like to change those parts through configuration. One can argue - this is already a good setup and when someone changes something, one can commit changes and keep track of the through git. Yes, with the same luck try to convince me that there are dragons. In practice, what happens in experimental mode is that many ideas are tried out together and code is not commited until a “stable” version is reached (whatever “stable” means here).
So how do we do it?
Option 1: Command line arguments
Let’s try to imagine the number arguments we would need to have to achieve a flexibility we want - meaning, making the red areas configurable. For the sake of demonstration I will show what steps might look like only for making DataModule configurable and some aspects of the Model training. Hopefully this will demonstrate shortcomings.
run.py - entry point of the application
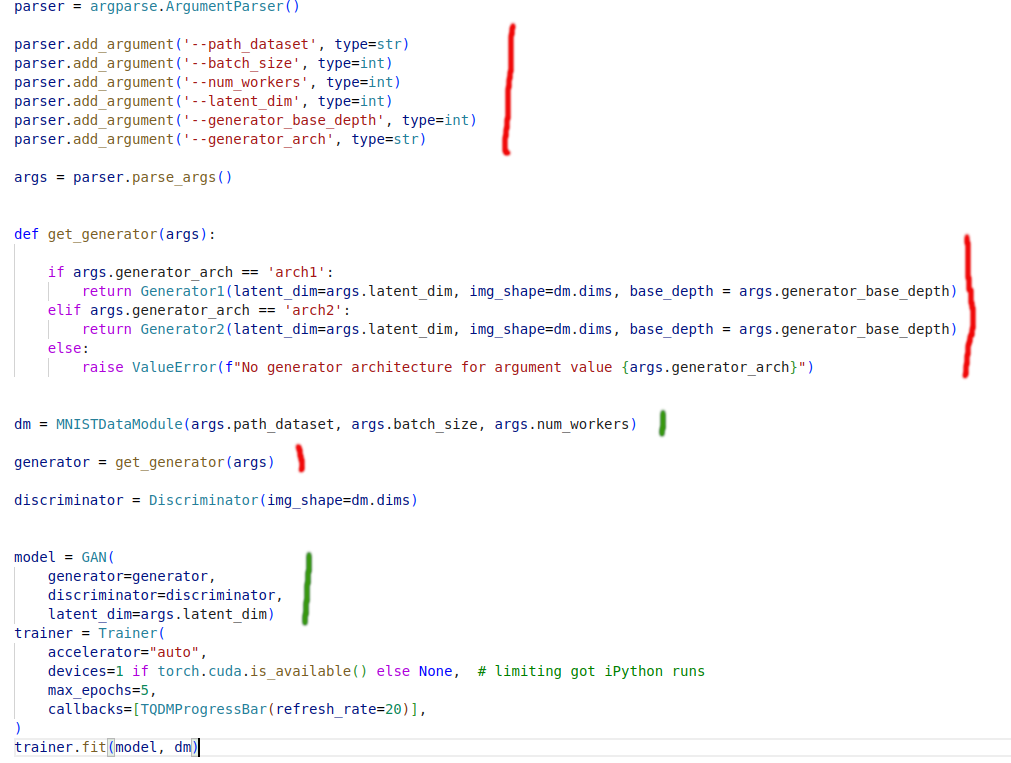
model.py - contains the PytorchLightning module and training logic
Pros
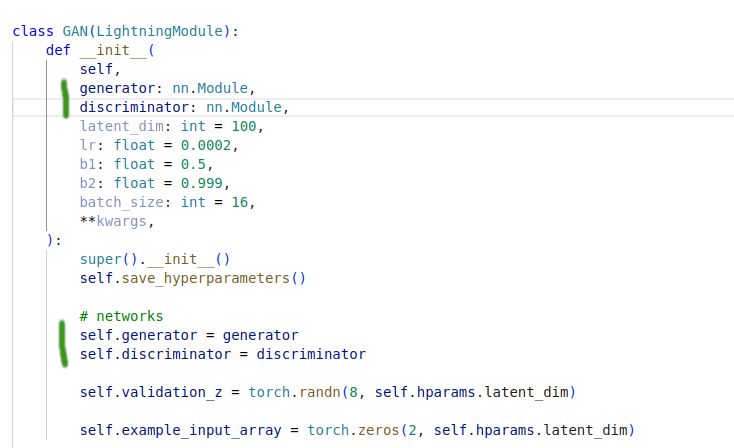
- injecting generator and discriminator to the LightningModule. Hardcoding generator and discriminator was a bad design choice from the very beginning. So I would not attribute this purely to configurability.
- There is another option, to pass configuration object to the LightningModule and create generator and discriminator inside. It is a BAD design choice, as it requires the user completely rely on configuration argument - know its structure and blow it up further as something additional is required.
- obvious one - it made some of the aspects of the project configurable.
Now to understand the cons, let’s look at the contents of the run.py
Cons
- in order to run this application my command will look like this
python run.py --path_dataset ../ --batch_size 256 --num_workers 64 --latent_dim 100 --generator_base_depth 128 --generator_arch arch1. And this is only for configuring small aspects of the dataset/dataloader and really negligible aspects of the generator. Imagine if- we need to add more information about the structure of the generator, discriminator, loss functions, optimizers.
- different generators have different configurable parameters
- different losses have different parameters
- different optimizers have different parameters
Handling everything will turn into a nightmare and the size of the command blow up into a poem. This will result in confusion and high cognitive load. One can keep some arguments to default, but this will only add to the confusion rather than elevate it. Imagine going through the code and figuring out why a particular value was passed to a certain function.
-
Only by looking at command line, there is no clear attribution of arguments to the entities they are intended to. One mitigation for this is using sub_parsers.
- pay attention to the
get_generator, now you will be forced to have a series of such functions for each customizable component (losses, optimizers …). Each generator might have different parametric structure, this will result in following- Every time one needs to try out a different generator, one needs to do back and forth between
get_generatorandargparseto understand which key values to pass - Every time one adds a new generator one needs to accomodate the same knowledge about its configuration in BOTH,
argparseandggt_generator.
- Every time one needs to try out a different generator, one needs to do back and forth between
- Having functions with structure of
get_generatoris not a good engineering practice and goes against SOLID principles - Last but not least, it adds the cognitive between purpose of particular argument and its implementation. As the argument intended for a DataLoader might be used for constructing model architecture. And there is no way of preventing that.
Option 2: Config yamls, tomls…
Let’s see what gets better and what gets worse…
config.yaml

run.py - entry point of the application
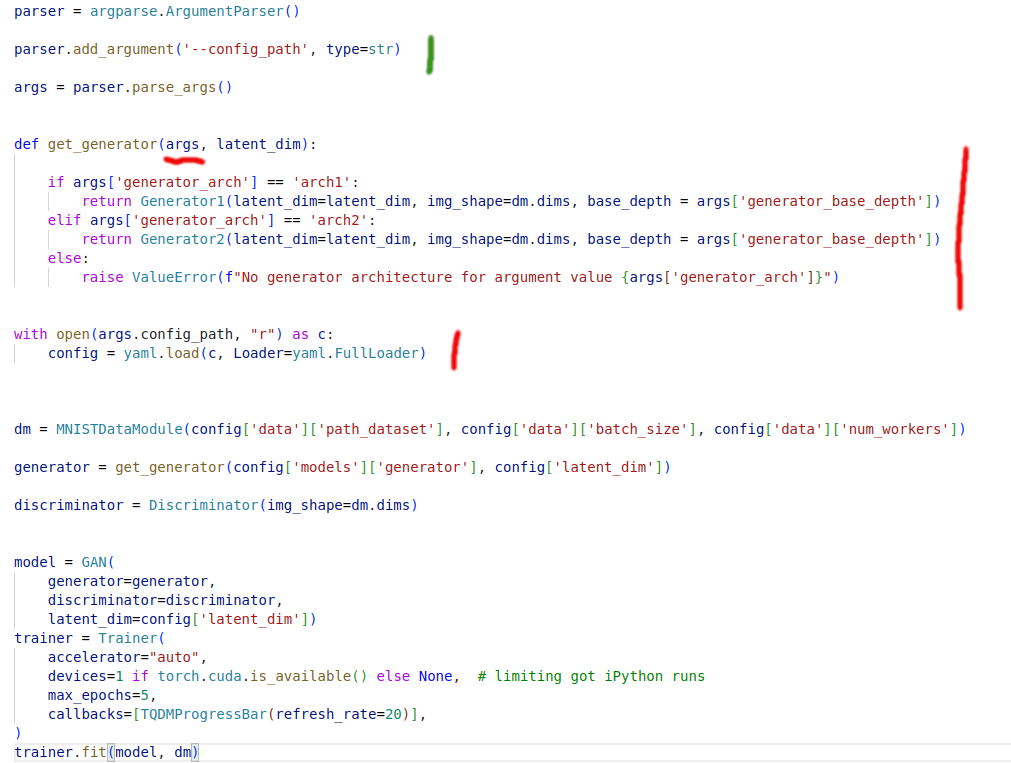
Pros
- Cleaner CLI, removes the confusion by adding consisenes
- Ability to natururally have nested structures
Cons
Basides the first point nothing really improved compared to Command Line arguments
- One still have to deal with functions like
get_generatorand all the headache assotiated with them - Problems with cognitive load and disonance did not go away
- Still a lot of
if/elsesin the code that is supposed to create objects in the code based on some configuraiton values e.g. - Additionally now parsed configuration is a dictionary, which means that user is free to add key/values (modify existing ones) in it. And I have witnessed a code examples where this is getting abused.
Solution: gin-configs
Now let’s see how gin-configs help you with above problems …
config.gin
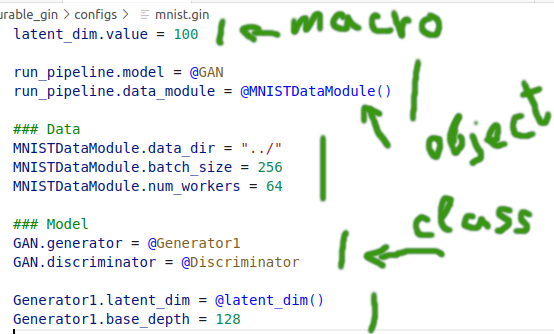
run.py - entry point of the application
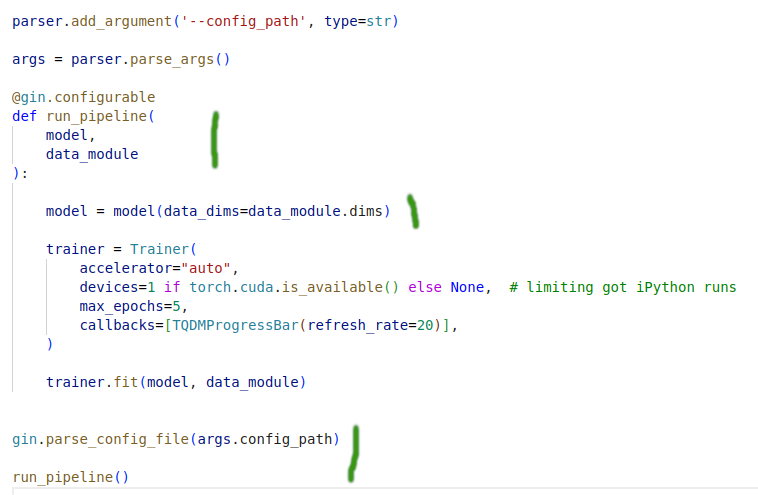
model.py - contains the PytorchLightning module and training logic
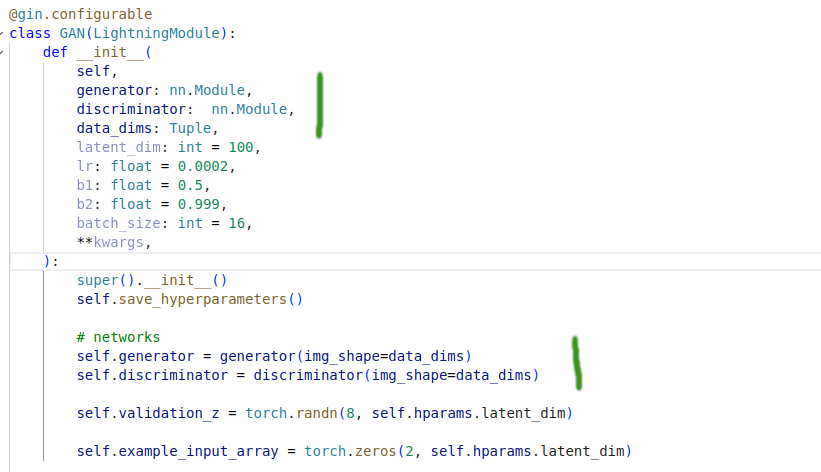
Pros (adding to the pros from yaml)
- Clear dependency between components defined in the configuration file
- Possibility to define a value in a form of a macro and pass it as a value to other object arguments
- No more functions as
get_generatoras entities and their interaction is directly defined in the config file - Logic is defined in one place - from the perspective of cognitive load one has to look at object definition and fill parameter values for object/function creation in the config
- Very hard to alter the configuration values, unless one of them is defined as a dictionary and afterwards altered in the application
- Minimal entry barrier - object/function becomes gin configurable as soon as
@gin.configurableis added as a decorator
Cons
- one shortcoming that I found is that one has to import all configurables e.g.
from arch.generators.generator import Generator1, Generator2even though one generator is used during one run. This will result tools likepylintcomplain about having unused imports.
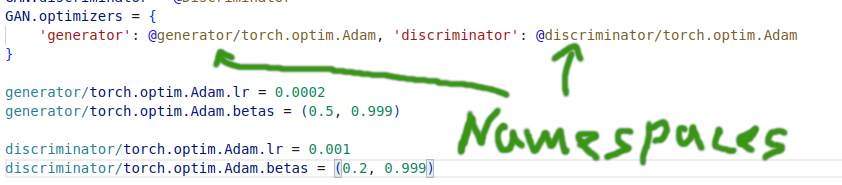
Above you have seen a nasty code snippet with optimizers…let’s see how we can leverage this elegantly with gin.
config.gin
model.py - contains the PytorchLightning module and training logic
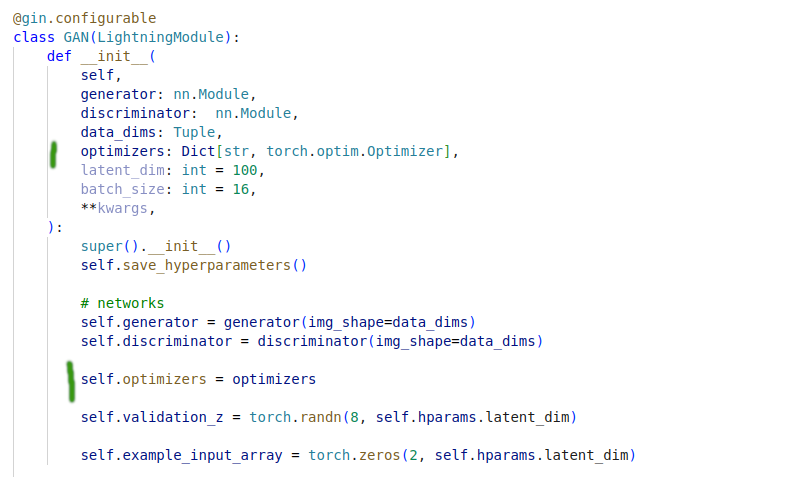

Notes
- Namespaces - are needed when multiple objects of the same class need to be created. Otherwise the last configuration values will be applied to every object
- Classes vs Objects:
- Objects - objects are created during runtime with parameter values defined in the config file
- Classes - whenever object is created, unless specified differently, default paramete values will be used from the config file.